

C vs C++11: C++ goes to eleven!
September 17, 2012
One of the top web results when searching for "C vs C++" is Jakob Østergaard's article of the same name. In his article, Jakob presents the challenge of writing a program that counts the unique words in a text file, and tries out various versions he got or created himself. Although Jakob's text can't really be considered a comprehensive comparison of C vs C++, it does provide some insight into how powerful C++ can be "out of the box".
The original C++ implementation given by Jakob is:
int
Unfortunately, the concise and highly readable solution presented above leaves a lot to be desired on the performance front. So, I set out to improve it, trying to also take advantage of any relevant C++11 features. My updated C++11 version is:
int
There are three changes in the new code. The first change is using the new C++11 std::unordered_set container instead of std::set. Internally, unordered_set uses a hash table instead of balanced tree, losing support for item ordering, but gaining significantly in average performance.
The second change is actually an old C++ option, not particular to C++11: disabling stdio synchronization. This is a big performance booster for intensive I/O. It is highly recommended to turn synchronization off, unless you really, really need to use the C and C++ standard streams at the same time.
The third change is explicitly taking advantage of C++11 move semantics (std::move()). In my benchmarks the change didn't have a noticable impact, perhaps because the compiler was eliding the copy anyway, or because the strings were small enough that a copy and a move weren't significantly different in performance.
To test the different versions, I created a series of word files containing 4 million words each, each one consisting of a different number of unique words. The tested versions include all the versions from Jakob's article, plus the new cpp4, c2, and python versions.
| Name | Description | SLOC |
|---|---|---|
| cpp1 | Original C++ version | 11 |
| cpp1-fixed | “Fixed” C++ version (using scanf) | 12 |
| cpp2 | C++ version of c1 | 100 |
| cpp3 | Jakob’s Ego-booster | 83 |
| cpp4 | C++11 version | 12 |
| c1 | C hash | 71 |
| c2 | Glib hash | 12 |
| py | Python | 5 |
Here are the run time results:
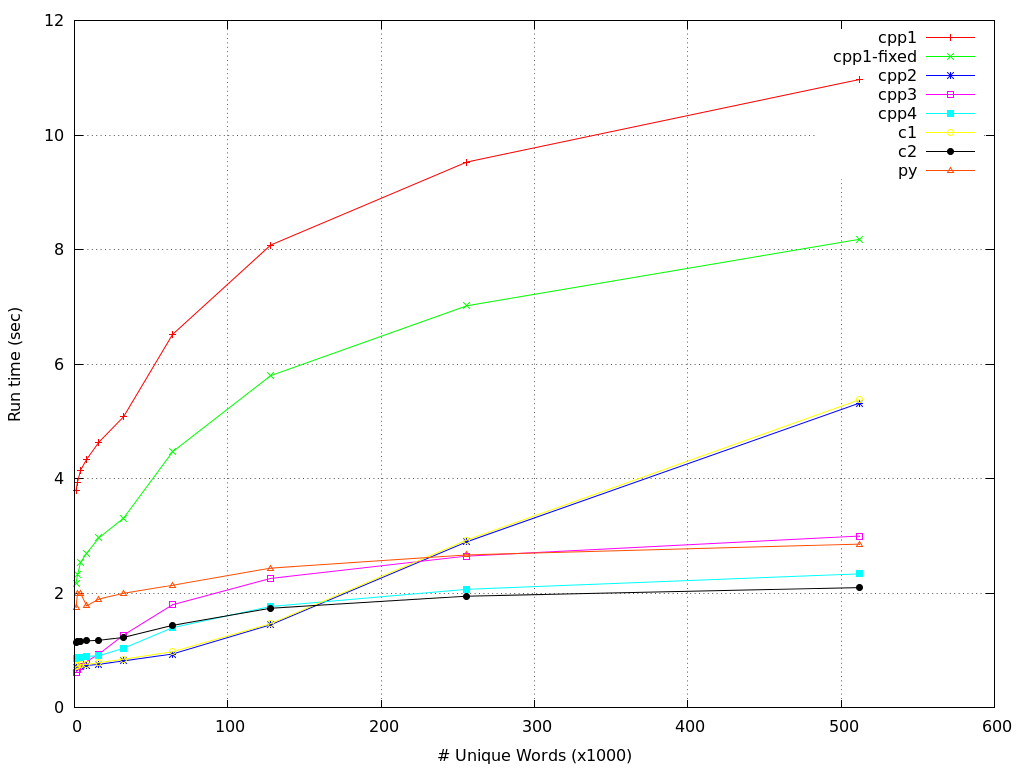
Here are the results for the maximum RSS:
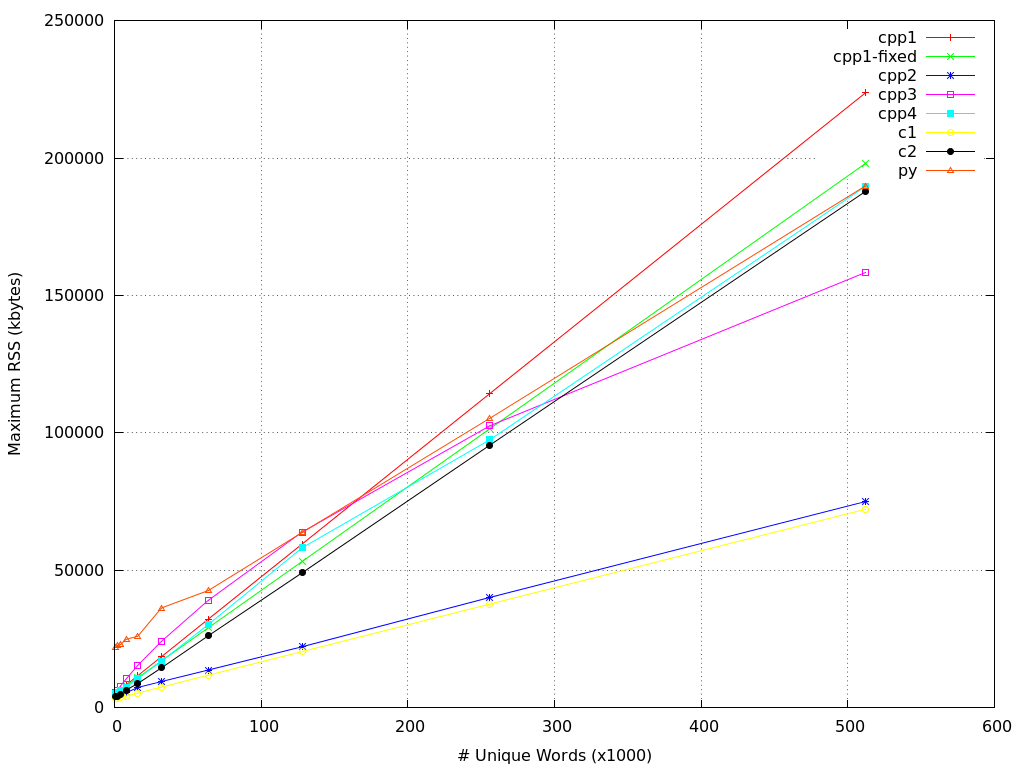
The updated C++11 version (cpp4) is about 5 times (!) faster than the original, partly because of using unordered_set, and partly because of not synchronizing with stdio. The memory usage has decreased by a decent amount, too! For lower numbers of unique words the performance results are somewhat mixed, but, as the number of unique words grows, the C++11 and Glib versions become clear winners. C++ goes to 11, indeed!
Based on the results above, here are some tips:
-
Rolling your own implementation is probably not worth it.
-
In C++11, when you don't need item ordering, you are probably better off using the unordered variants of the containers (but don't forget to benchmark).
-
If you use standard streams, and don't need to be in sync with stdio streams, be sure to turn synchronization off. If you need to be in sync, try hard to stop needing it!
-
If you just want to quickly create something having decent performance, consider using python.
You can find the code and scripts used for benchmarking here. To create the sample text files ('make texts') you need to have an extracted copy of scowl in the project directory.